Image-to-3D generation aims to predict a geometrically and perceptually plausible 3D model from a single 2D image.
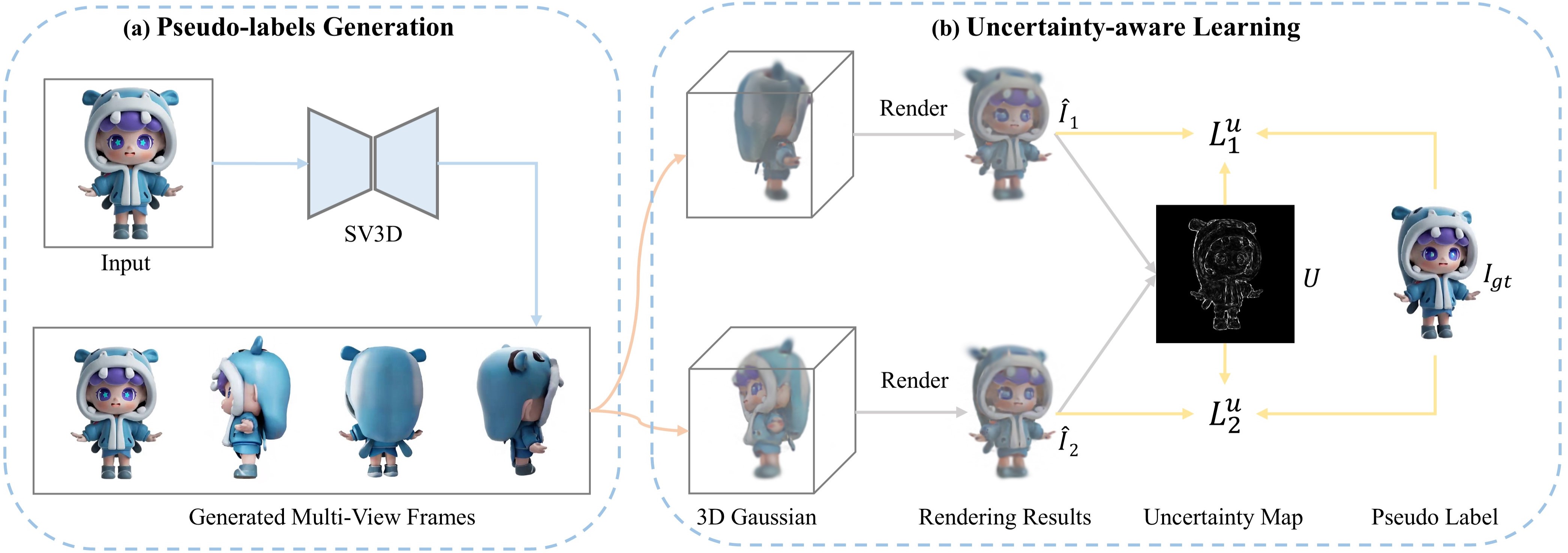
Conventional approaches typically follow a cascaded pipeline: initially generating multi-view projections from the single input image through view synthesis, followed by optimizing 3D geometry and appearance strictly using these projections.
However, such deterministic optimization neglects epistemic uncertainty from imperfectly generated data, particularly due to limited observations and inconsistent content.
To address this issue, we propose an uncertainty-aware optimization framework that explicitly models and mitigates epistemic uncertainty, leading to more robust and reliable 3D generation.
For epistemic uncertainty arising from incomplete viewpoint coverage, we employ a progressive sampling strategy that dynamically varies camera elevations and progressively integrates diverse viewpoints into training, enhancing viewpoint coverage and stabilizing optimization.
For epistemic uncertainty caused by the deterministic optimization on the noisy and inconsistent generated multi-view frames, we estimate an uncertainty map from the discrepancies between two independently optimized Gaussian models.
This map is incorporated into uncertainty-aware regularization, dynamically adjusting loss weights to suppress unreliable supervision.
Furthermore, we provide a theoretical analysis of uncertainty-aware optimization by deriving a probabilistic upper bound on the expected generation error, providing insights into its effectiveness.
Extensive experiments demonstrate that our method significantly reduces artifacts and inconsistencies, leading to higher-quality 3D generation.